
DeepSeek’s Bet That Efficiency Can Compete With Scale
A lab that was not under obvious financial pressure just raised the largest AI funding round in Chinese history.

We've been tracking DeepSeek's unusual trajectory from the start. Back in March 2025, we detailed how DeepSeek was rewriting the AI playbook through a combination of genuine efficiency gains in model design and an open-source strategy that forced an industry-wide reassessment. More recently, in May 2026, we mapped the ten distinct business systems behind China's AI landscape, showing how DeepSeek occupies a unique position among Chinese frontier labs—one defined not by a single commercial pillar but by research culture and technical efficiency. This piece is the next step in that thread.
Things you might have missed
A few stories from our recent coverage that are worth your time.
From our recent coverage:
MiniMax’s market cap has fallen roughly 65% since its March 2026 peak, erasing more value than most Chinese AI companies have ever been worth. But the underlying numbers don’t support a simple narrative of fundamental failure. (Read more)
BYD executive VP Stella Li told CNBC that the company aims for 75% of vehicles sold in Europe to be produced locally—less a defensive trade-war hedge and more the next phase of converting export volume into local production capacity. (Read more)
WeChat opened its AI platform to mini-program developers, letting users swipe to an AI assistant that can book rides, order food, and purchase tickets. The move echoes the mobile-era platform wars between Tencent and Alibaba. (Read more)
From Weijin Research:
Weijin Research recently reassessed DeepSeek-V4, arguing that a capability gap averaging around seven months persists against Western frontier models—driven not just by compute limitations but by differences in data quality, training environments, and enterprise demand. (Read more)
Founder Liang Wenfeng has been unusually clear about what he sees as DeepSeek’s biggest risk. It is not compute, regulation, or U.S. frontier labs. It is talent.
“For DeepSeek, our core priority is ensuring team stability,” he said during a mid-May investor briefing. “This matters more than money or resources. This is our biggest risk, and our biggest challenge.”

That view helps explain a funding round that otherwise looks unusual. DeepSeek already generates positive inference margins, spends little on sales, and was incubated inside a quantitative hedge fund with the resources to support it for years. Yet it reportedly completed the largest AI funding round in Chinese history.
DeepSeek’s view is not that capital does not matter. It is that talent and engineering efficiency determine how much progress a lab can extract from every dollar it spends. In DeepSeek’s telling, sanctioned chips and smaller budgets are not simply obstacles to overcome. They are constraints that force a lab to extract more intelligence from every unit of compute, lower serving costs, and redirect resources back into research.
Whether that belief is right is becoming one of the most important questions in AI.
The Round Nobody Expected
DeepSeek’s financing is unusual not because it raised money, but because of the terms on which it raised it.
During OpenSourceWeek, its early-2025 run of daily open-source releases, the company disclosed an inference business generating a theoretical 545% cost-profit margin: roughly $87,000 in daily costs against $562,000 in daily revenue. This is the lab that turned R1 into a global event and repeatedly shipped frontier-level models at a fraction of Western costs while keeping its weights open. Unlike many AI startups, DeepSeek had already shown it could generate revenue without aggressive commercialization and without depending on outside investors for day-to-day survival.
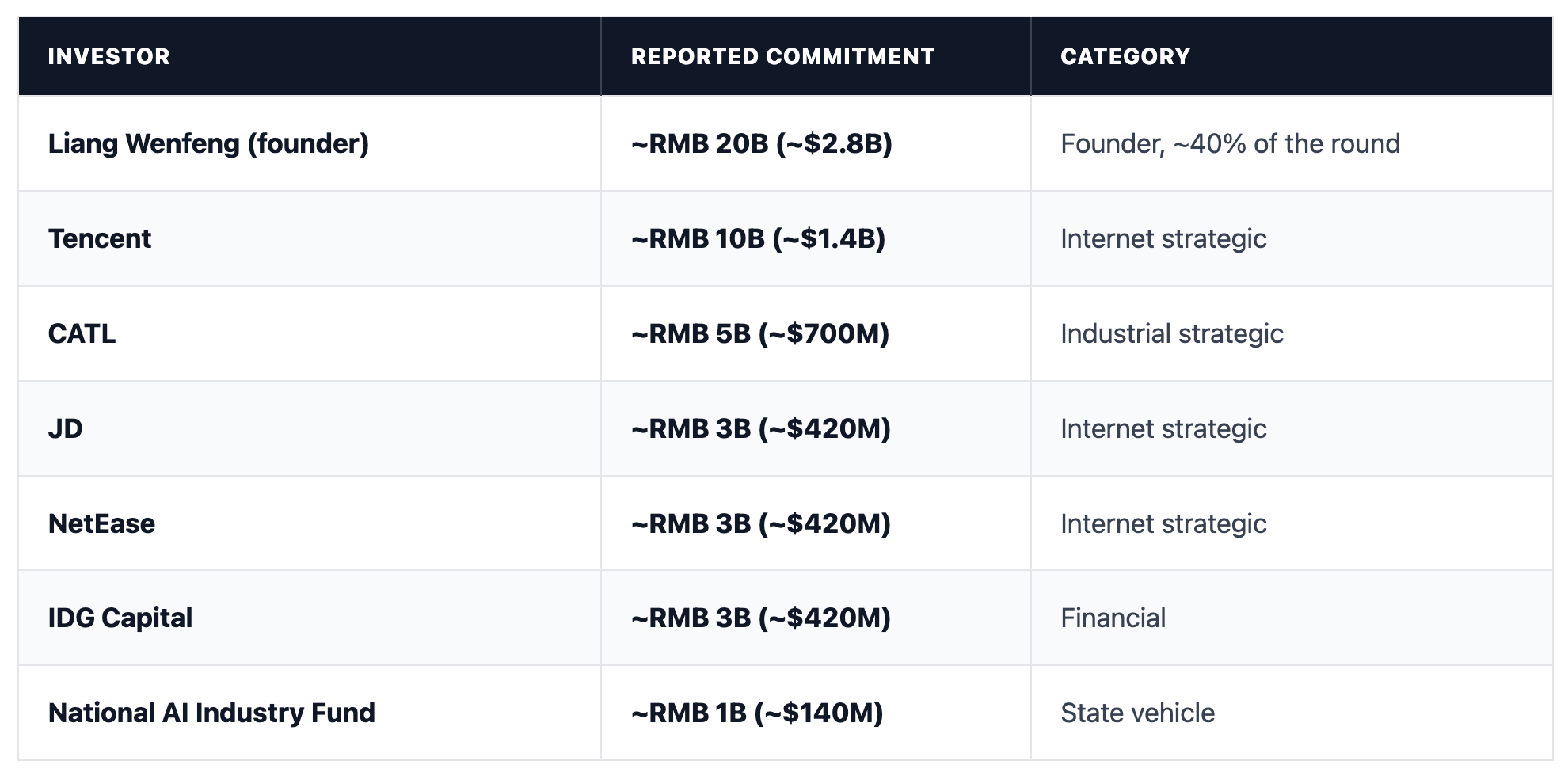
Yet it reportedly completed the largest AI funding round in Chinese history. The round closed in mid-June at more than RMB 50 billion ($7 billion+), after opening in April at a valuation near $10 billion and finishing above $50 billion. Liang Wenfeng himself reportedly contributed as much as RMB 20 billion ($2.8 billion), roughly 40% of the total and more than any single institutional investor.
One investor involved in the round reportedly worried that DeepSeek had become “too consensual” an investment. Another described the company in almost philosophical terms: “They are doing all of this with tremendous goodwill. It’s as if he’s telling us: this is how the world is supposed to be.”
The round is best understood not as operating capital but as strategic capital. DeepSeek already had the resources to continue training models and funding research. The financing strengthens employee ownership, extends research runway, and allows Liang to bring in partners while preserving control. If talent is the company’s primary bottleneck, the value of the round lies less in funding the next training run than in protecting the people and culture that produced the previous ones.
The question is whether talent really is the constraint Liang believes it to be.
Holding the Team
Team stability is the risk Liang Wenfeng keeps pointing to, but the numbers suggest DeepSeek has held together remarkably well. Across the 391 authors listed on DeepSeek’s 27 technical papers, only 25 have left, an attrition rate of 6.4%. Among the 15 researchers who appear most frequently across DeepSeek LLM, V2, and V3, only two have departed.
The departures that did happen were highly visible. Guo Daya, a key contributor to R1, joined ByteDance Seed on a package reportedly worth close to RMB 100 million ($14 million) annually. Wang Bingxuan, a core author of DeepSeek’s first model, moved to Tencent Hunyuan. Luo Fuli, a key V2 developer, now leads Xiaomi’s MiMo team. Liang was explicit with investors: one of his conditions was that they not poach DeepSeek employees or fund competing spinouts.

DeepSeek is unlikely to become the highest bidder for AI talent. Instead, it relies on impact, equity, and mission. When R1 became the most-downloaded model on Hugging Face and its techniques spread across dozens of labs, the researchers behind it gained recognition that is difficult to replicate inside a closed-source organization. The funding round also gives employee ownership a credible valuation, making stock options a more meaningful retention tool.
Liang has repeatedly framed the mission in national and technological terms: “China inevitably needs someone to stand at the frontier of the technology.” Just as importantly, he has kept it narrow: “We will only do things related to advancing intelligence. We won’t do anything else.”
Why Efficiency Matters
A person close to DeepSeek estimates the lab spends $300–500 million annually, with a frontier training run costing only tens of millions of dollars. Against that backdrop, a RMB 50 billion ($7 billion+) funding round looks less like a budget than a reserve.
Leading American labs now spend tens of billions of dollars annually on compute alone, and Anthropic’s reported compute commitment with SpaceX is roughly $15 billion per year. Yet one recent expert assessment still measured the capability gap in months rather than years. If that estimate is even directionally correct, capital alone cannot explain frontier performance.
At DeepSeek, efficiency and capability are closely linked. The same mixture-of-experts architecture that reduced costs in V3 also enabled a 671-billion-parameter model to operate with roughly 37 billion active parameters. Lower cost is the visible result; more capability per unit of compute is the more important one.
Export controls make this especially relevant for China. American labs can continue scaling by adding GPUs. Chinese labs have far fewer options. DeepSeek’s bet is that the winner will not be the lab that spends the most, but the one that gets the most intelligence out of every chip and every dollar.
That bet only works if DeepSeek can consistently turn constraint into capability. V4 validated DeepSeek’s expert-parallelism scheme on Huawei Ascend chips alongside Nvidia’s, while reducing dependence on Nvidia’s software stack through more portable infrastructure such as TileLang. The migration remains incomplete, but each new model lowers the cost of finishing it.
The efficiency gains are substantial. At a one-million-token context, V4-Pro uses roughly 27% of its predecessor’s inference FLOPs per token while reducing KV cache requirements to about 10%. DeepSeek’s own hardware report acknowledges that much of the architecture was designed around the limitations of available chips. The result is not just lower cost but higher capability. V4-Pro ranks just behind Gemini-Pro-3.1 on Artificial Analysis’s intelligence index, while R1, DeepSeekMath-V2, and the lab’s reward-modeling work all demonstrate how engineering improvements can be converted into frontier performance.
The economics follow from the same foundation. V4’s Pro and Flash tiers are separated by roughly a 12x output-price difference, with the cheaper tier already capable of running on less advanced hardware. Domestic chips are expected to satisfy an estimated 40–50% of China’s inference demand this year. Because DeepSeek spends little on traditional go-to-market activities, price is a central part of its strategy. But permanently low prices only work if compute costs continue falling, and that depends on the company’s ability to keep extracting more performance from the hardware available to it.
Capital Without Control
If DeepSeek is right that talent and research matter more than capital, then the funding round had to provide capital without giving up control. The resulting investor roster looks less like a venture syndicate and more like a coalition of Chinese industrial, financial, and state-backed interests.
Underneath the headline investors sits a more complex ownership structure. Fund documents show roughly 100 institutions and individuals participating through about 10 investment vehicles, with most capital routed through partnerships controlled by Liang rather than invested directly. Reported participants include Monolith, IDG, entities linked to Nongfu Spring, Septwolves, and iHealth, and a late investment from Loyal Valley Capital.
Control appears to be the central design principle. Before the round, Liang increased his direct stake from 1% to 34%. Including affiliated entities, he reportedly retains 84% of the economics and 100% of the voting power, with a five-year lockup for other investors. An earlier report put his combined control even higher, at 89.5%. Either way, investors are buying economic exposure and access, not governance rights.
The state’s role is meaningful but limited. Its roughly RMB 1 billion investment is the only reported direct stake in DeepSeek itself and comes through the National AI Industry Investment Fund, a RMB 600 billion vehicle backed by the National IC Fund (“Big Fund”) Phase III. The arrangement gives Beijing visibility without control.
The strategic investors tell a similar story. CATL’s reported RMB 5 billion investment complements its broader push into AI-related compute and power infrastructure, while Tencent’s reported RMB 10 billion investment ties China’s largest consumer platform more closely to an open-model provider it already uses. Just as notable are the absences: Sequoia, Hillhouse, and Alibaba reportedly stayed out.
The result is a structure that preserves founder control, limits outside influence, and brings in partners seeking access rather than oversight.
Beyond DeepSeek
The ownership structure explains how DeepSeek intends to preserve control. What matters next is how that control gets used.
DeepSeek has already demonstrated that it can build frontier models efficiently. The more interesting question is whether that approach can scale beyond DeepSeek itself.
There are signs that it already is. In mid-June, Zhipu released GLM-5.2 under an MIT license with a one-million-token context window and coding performance approaching leading Western models while charging a fraction of the price. More importantly, while DeepSeek still relies on Nvidia for much of its training, Zhipu trained the GLM-5 family on Huawei Ascend. The significance is less the benchmark result than the pattern it represents. Multiple Chinese frontier labs are now pursuing the same basic idea: use engineering efficiency, open models, and domestic infrastructure to narrow a gap that many assumed could only be closed through vastly larger compute budgets.
That influence is increasingly extending beyond China. This week, Axios reported that Microsoft is considering DeepSeek as a lower-cost model option within Copilot Cowork, its enterprise AI agent platform. Whether or not that deployment ultimately happens is less important than the fact that one of the world’s largest software companies is evaluating DeepSeek as part of its production AI stack rather than as a niche open-source alternative.
Viewed from this perspective, the financing, the open-source strategy, and the emphasis on efficiency begin to look like parts of the same system. The capital helps preserve the team. The team develops new approaches. Open distribution allows those approaches to spread beyond DeepSeek itself, while other labs increasingly test and refine similar ideas.
The round is striking not because DeepSeek raised money, but because it raised so much money while insisting that money is not its primary constraint. Liang has repeatedly said that talent is the company’s biggest risk. The structure of the financing suggests he means it. Investors received economic exposure, but very little influence. The company gained billions of dollars of additional resources while largely preserving the culture, ownership structure, and research agenda that existed before the round.
Most startups raise capital to change what they can do. DeepSeek appears to have raised capital to keep doing what it was already doing.